How LLMs Work
Large language models are the technology behind ChatGPT, Claude, DeepSeek, and others. An LLM is a system trained on an enormous amount of data that predicts the next token given a sequence of previous tokens.
Training vs inference
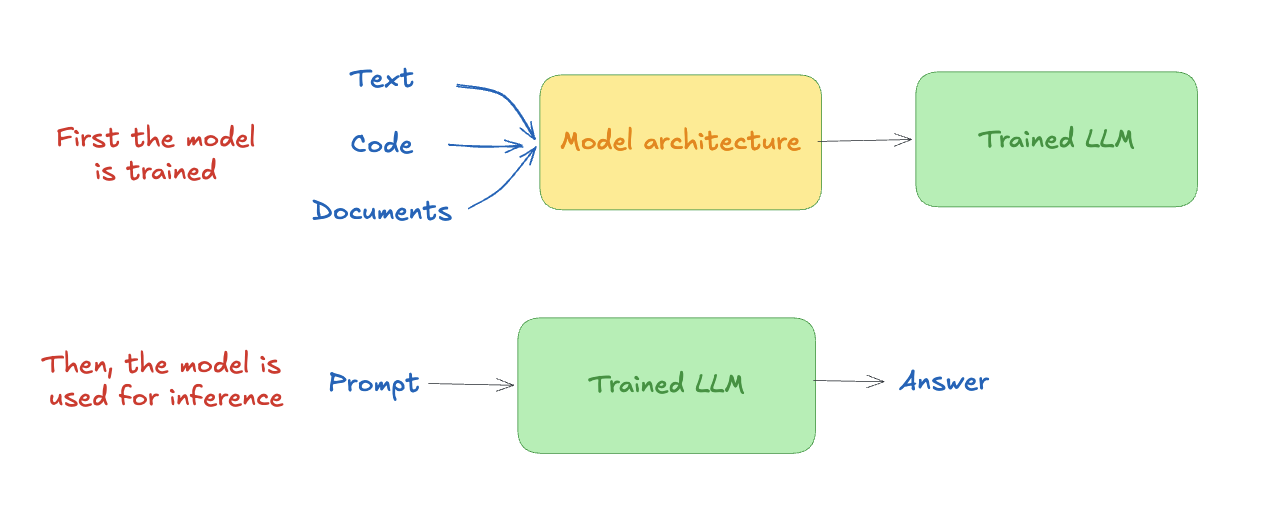
Before a model can predict anything useful, it must be trained. Training exposes the model to vast amounts of data and gradually adjusts billions of numerical parameters, called weights, so that its predictions improve over time.
By the time you download and run a model, training is already done. The weights are fixed. Inference is just the model using what it already learned.
Model architecture
Most modern LLMs are built on the Transformer architecture. At a high level, an LLM is composed of 3 main components:
- an Embedding layer
- a stack of Transformer layers
- an LM Head

In this article, we will follow the path of a prompt through these steps.
How does inference work?
Let’s consider, at a high level, the steps involved during inference, so we can understand how an answer is generated from a user’s prompt.

In the following sections, we’ll detail each box of the diagram.
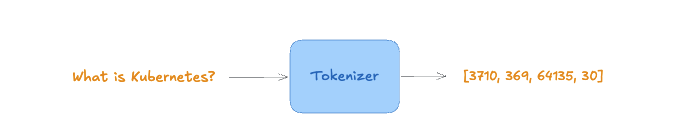
Tokenizer: from text to token IDs
Before the model can process the prompt, it is split into tokens, then converted into a list of IDs. This process is performed by a Tokenizer.
Check the Tokenizer article to learn more.
Forward pass
The forward pass is the journey of one or more token IDs through the model. During that journey, the Embedding layer, the Transformer layers, and the LM Head are applied sequentially, producing logits.
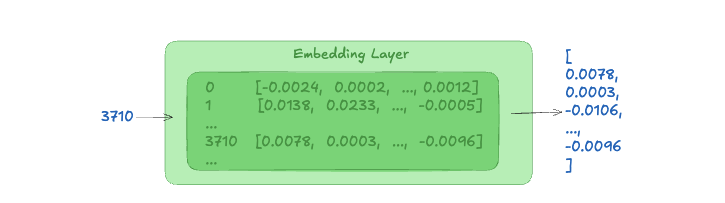
- Embeddings: from a token ID to high-dimensional vectors
For each token ID, the model retrieves a high-dimensional vector, called an embedding. Embeddings are learned numerical representations that capture semantic relationships between tokens. These representations are learned during training.
Check the Embeddings article to learn more.
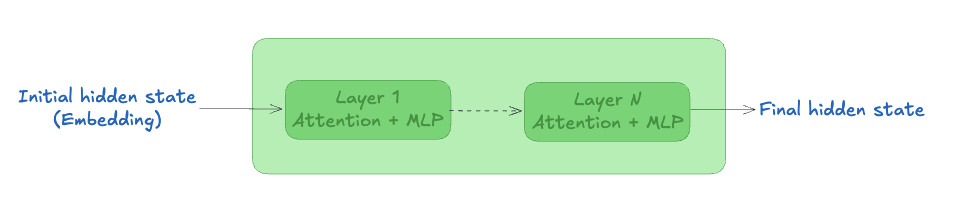
- Going through the Transformer layers
The embedding becomes the token’s initial hidden state. It is enriched while it flows through each Transformer layer. In each layer, the Attention and MLP steps are performed. After the final Transformer layer, the hidden state has become the token’s final representation.
Attention adds information from other tokens prior in the sequence to the token’s hidden state.
MLP adds information that the model learned during training to the token’s hidden state.
Attention figures out what’s relevant. MLP knows what things mean.
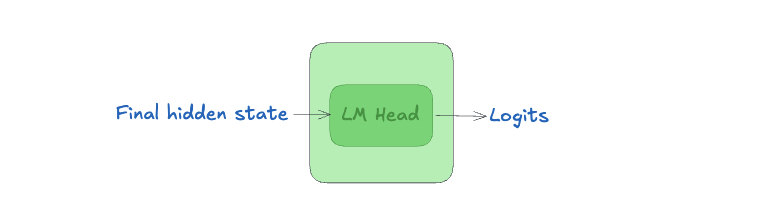
- LM Head Producing Logits
After the last transformer layer, the LM Head produces a score (logit), based on the final hidden state, for every token in the vocabulary.
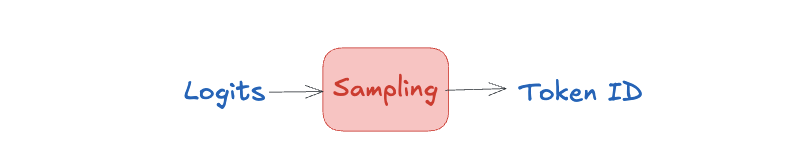
Selection of the next token
After the model produces the logits, a sampling algorithm then selects the next token using parameters such as Temperature, Top-P, and Top-K.
After a token ID is generated, a new tokenizer step to used to convert the token ID back to text.
Repeat
When the next token is generated, it is appended to the output sequence and the model continues generating the next token, starting a new forward pass with the last token ID as input.
Prefill vs decode: the two main phases at runtime
prefill and decode are 2 steps that perform the forward pass:
- prefill computes the entire prompt at once
- decode operates one token at a time
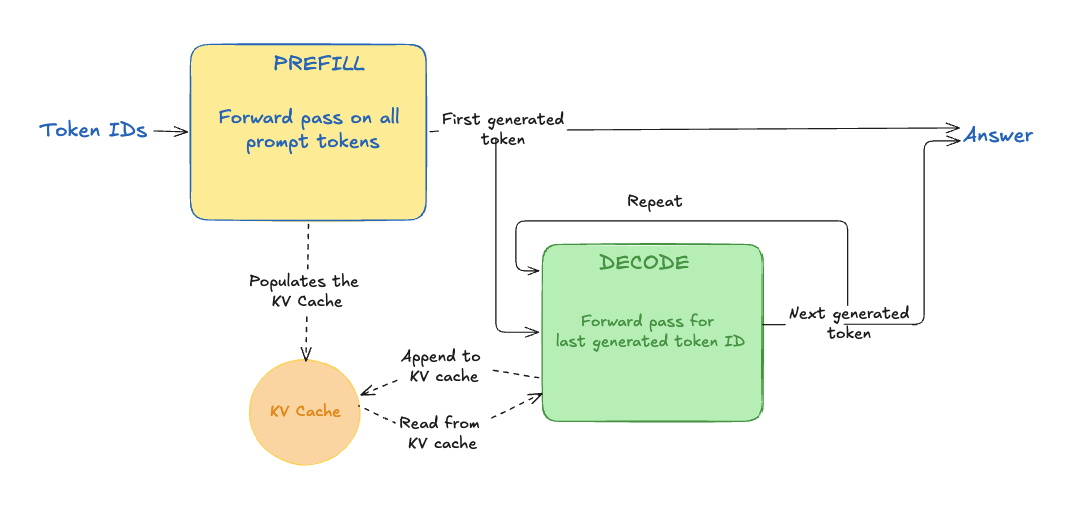
For each token within the prompt, the prefill step creates a K/V cache entry for each transformer layer. The decode step also contributes to the KV cache, adding an entry for each layer for the current token.
KV Cache
The KV cache stores, for every previous token and every transformer layer, the Key and Value vectors that capture the token’s representation at that layer. During decoding, these cached vectors are compared with the new token’s Query to compute attention, allowing the model to determine which previous tokens are most relevant.
Key Takeaways
During inference, the user’s text prompt is first split into tokens, which flow through the transformer layers. Within each layer, attention determines which previous tokens are relevant and the MLP applies the stored knowledge. Then scores are computed for every possible next token. A sampling algorithm then selects the next token using various parameters.